Antimicrobial resistance (AMR) molecular Resistomes, Variants, & Prevalence data were generated using the Resistance Gene Identifier (RGI), a tool for putative AMR gene detection from submitted sequence data using the AMR detection models available in CARD. To generate Resistomes, Variants, & Prevalence data, RGI was used to analyze molecular sequence data available in NCBI Genomes for 414 pathogens of interest, plus genomic islands available in Islandviewer. For each of these pathogens, complete chromosome sequences, predicted genomic islands, complete plasmid sequences, and whole genome shotgun (WGS) assemblies were analyzed individually by RGI. RGI results were then aggregated to calculate percent occurrence. For example, if 50 WGS assemblies were analyzed and blaNDM-1 was predicted by RGI in 40, the calculated prevalence would be 80%. Results are further categorized using the Antibiotic Resistance Ontology (ARO), e.g. "beta-lactam resistance protein", "antibiotic inactivation enzyme", etc.
Resistomes, Variants, & Prevalence data is available under both the Perfect and Strict paradigms of RGI, the former tracking perfect matches to the curated reference sequences and mutations in the CARD, while the latter detects previously unknown variants of known AMR genes, including secondary screen for key mutations, using detection models with curated similarity cut-offs to ensure the detected variant is likely a functional AMR gene. These analysis currently exclude CARD's rRNA mutation models. For more information, see the Resistance Gene Identifier.
The reported results are entirely dependant upon the curated AMR detection models in CARD and the sequence data available at NCBI and Islandviewer. Reported frequencies have not been corrected for unmeasured clonality or sampling bias of genomic data available at NCBI. These data will change over time as CARD curation, RGI software, and NCBI data evolve.
Additional data have been provided by the Canadian Genomics R&D Initiative on AMR One Health, via NCBI BioProject PRJNA1076250.
CARD Resistomes, Variants, & Prevalence 4.0.1 is based on sequence data acquired from NCBI on May 2, 2023 and Islandviewer 4, analyzed using RGI 6.0.2 (DIAMOND homolog detection) and CARD 3.2.7.
Usage: (1) CARD Resistomes, Variants, & Prevalence can be downloaded for bulk analyses, including assessment of thousands of individual sequenced isolates. (2) The CARD website uses these data to summarize the molecular epidemiology of individual resistance genes, e.g. NDM-1. (3) The Resistance Gene Identifier can use these sequences variants as a broader reference set for analysis of metagenomics data using read-mapping. (4) The Resistance Gene Identifier can use k-mers derived from these data for pathogen-of-origin prediction for antimicrobial resistance gene sequences.
The number of completely sequenced genomes, completely sequenced plasmids, whole-genome shotgun assemblies, or genomic islands analyzed for each pathogen. All sequence data acquired from NCBI Genomes and Islandviewer.
| Species | NCBI Chromosome | NCBI Plasmid | NCBI WGS | NCBI GI | GRDI-AMR2 |
|---|
|
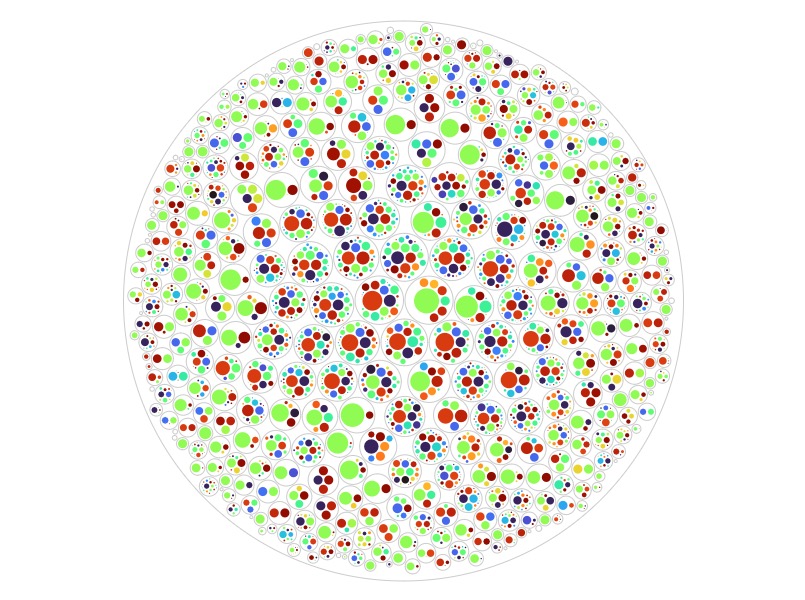
AMR Gene Mobility: Big circles are pathogens, little circles within are genes. Size of little circles reflects prevalence in WGS data. Genes exclusively on chromosomes in white, others increasingly blue based on association with plasmids. Does not include efflux. |
|---|
|
Drug Classes Impacted: Big circles are pathogens, little circles within are ARO Drug Classes. Size of little circles reflects prevalence in WGS data. Colours reflect Drug Class combinations. Does not include efflux. |
Prevalence of AMR genes and variants organized by CARD detection model. Values reflect percentage of completely sequenced genomes, completely sequenced plasmids, whole-genome shotgun assemblies, or genomic islands that have at least one hit to the AMR detection model. The search box can be used to filter results by gene family names (e.g. TEM-), pathogens (e.g. Pseudomonas), or the ARO categories used in the Phenotype table above (e.g. macrolide). Multiple search terms will search for entries containing all given terms. For more complex queries, please Download the full data set.
| Gene | Species | NCBI Chromosome | NCBI Plasmid | NCBI WGS | NCBI GI | GRDI-AMR2 |
|---|